mysql 优化
配置文件
[mysqld]
binlog_format=mixed
OPTIMIZE 优化表
OPTIMIZE TABLE table_name;
会重组表数据和索引的物理存储,减少对存储空间使用和提升访问表时io效率。
索引说明
system>const>eq_ref>ref>range>index>ALL (越左边,查询速度越快)
1、system级别 A、只有一条数据的系统表 B、或衍生表只能有一条数据的主查询
很明显 实际开发当中 我们是不会只有一条数据的
2、const级别 仅仅能查出一条的SQL语句并且用于Primary key 或 unique索引; SELECT * from shop s where s.id=? 主键索引、唯一索引和unique索引达到这个级别,我们写sql要根据公司的业务去写,这个情况也很难达到的。
3、eq_ref级别 唯一性索引:对于每个索引键的查询,返回匹配唯一行数据(有且只有1个,不能多,不能0); 比如你select …from 一张表 where 比方说有一个字段 name = 一个东西,也就是我们以name作为索引,假设我之前给name加了一个索引值,我现在根据name去查,查完后有20条数据,我就必须保证这二十条数据每行都是唯一的,不能重复不能为空!
只要满足以上条件,你就能达到eq_ref,当然前提是你要给name建索引,如果name连索引都没,那你肯定达不到eq_ref;
此种情况常见于唯一索引和主键索引;
比如我根据name去查,但是一个公司里面或一个学校里面叫name的可能不止一个,一般你想用这个的时候,就要确保你这个字段是唯一的,id就可以,你可以重复两个张三,但是你身份证肯定不会重复;
添加唯一键语法:alter table 表名 add constraint 索引名 unique index(列名)
检查字段是否唯一键:show index form 表名;被展示出来的皆是有唯一约束的;
4、ref级别 ref级别的问题不大。
非唯一性索引:对于每个索引键的查询,返回匹配的所有行(可以是0,或多个)。
假设有俩张三,我建立了非唯一索引,那么查出来就是这个级别拉,是不是很简单。
5、range级别 检索指定范围的行,查找一个范围内的数据,where后面是一个范围查询 (between,in,> < >=); in有时有可能会失效,导致为ALL;
6、index级别 把索引的数据全查出来 就是这个级别了
7、ALL级别 不做索引 就是all级别咯
and 查询
select * from `movies` where (`api_id` = 36 and (`type_id` in (1, 6, 7, 8, 9, 20))) order by `updated_at` desc limit 24 offset 24;
优化方案
# 显示索引
SHOW INDEX api_id_type_id from movies;
# 创建索引
CREATE INDEX api_id_tyoe_id on movies(api_id,type_id)
#删除索引
DROP index api_id_type_id on movies;
索引的使用
mysql最左原则
create index idx_name_phone on user(name,phone);
当我们查询数据库的时候,以下查询会走索引,name 查询在前,phone 在后
select * from user where name like 'oranggbus%' and phone like '1830001%'
不会走索引,因为 创建的索引 name 在前,phone 在后
select * from user where phone like '1830001%' and name like 'oranggbus%'
2、范围查询右侧的查询会失效
select * from user name="" and age > 10 and status=1; // status 会失效
3、索引进行运算会失效
select * from user where substring(phone,10,2) = "15"; // phone 索引进行了运算
4、字符串索引查询 不加 单引号,索引失效
select * from user where phone = 1830000001;
5、模糊查询:头部匹配,索引失效,尾部匹配,不会失效
select * from user where name like 'oranggbus%' // 不会失效
select * from user where name like '%oranggbus%' // 失效
6、or查询:
有索引 or 没有索引 = 涉及到的索引不会用到
有索引 or 有索引 = 涉及到的索引会用到
7、分布影响
覆盖索引
使用索引,并且在返回的列,在该索引中已经全部找到,减少 select *
using index condition 使用索引,需要回表
using where susing index 使用索引,返回数据在索引列中能够找到,不需要会表查询
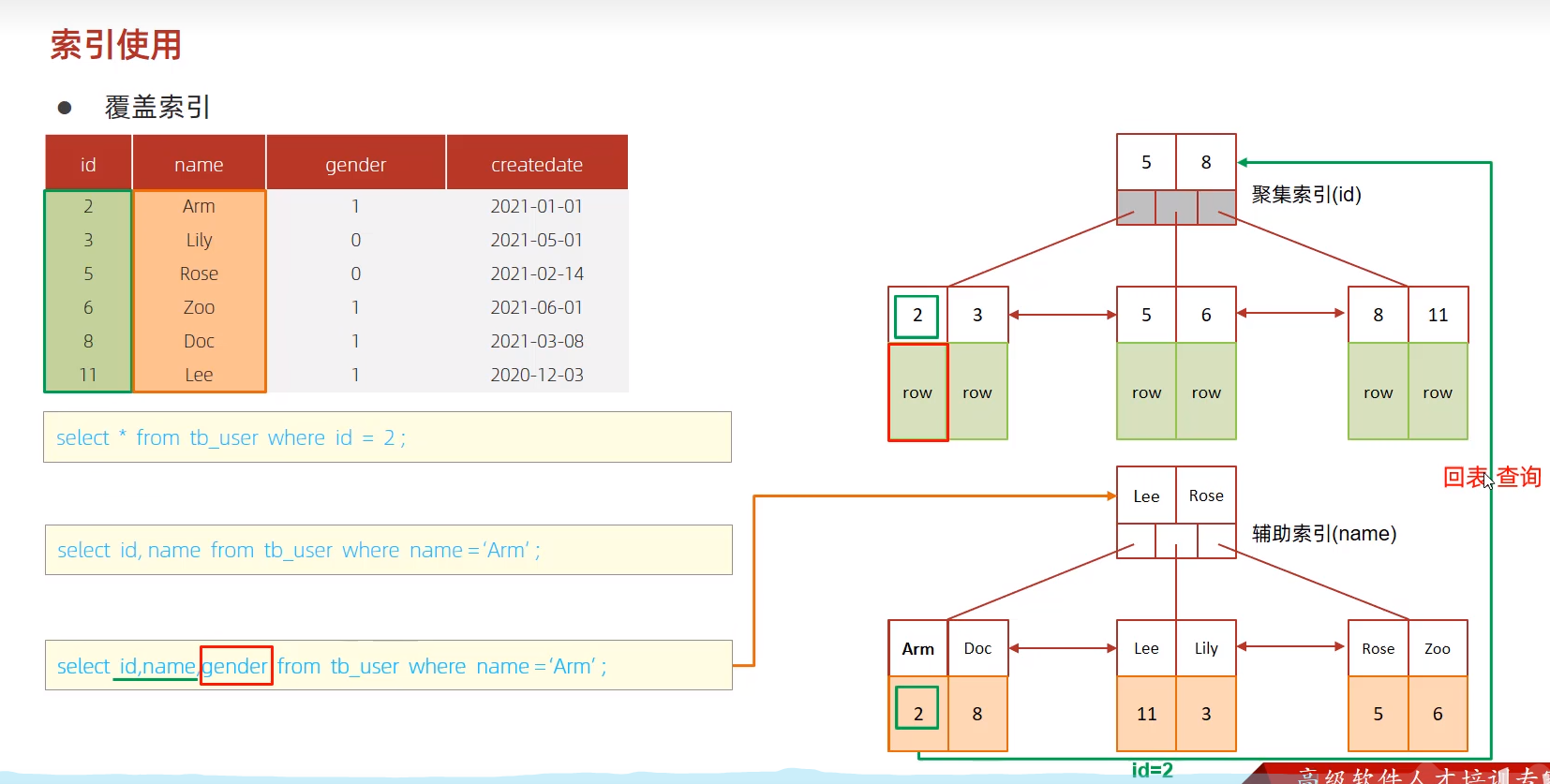
回表查询:使用覆盖索引查询的时候,返回的结果中有额外的字段,需要回表二次查询
前缀索引
长文本字段查询,减少索引体积,减少io,提高查询效率
提取一个长文本的前几个字符建立索引
create index idx_xx on table_name(colume(n))
create index idx_title_26 on articles(title(26));
如果选择长度
select count(distinct substring(title,1,10))/count(*) from article;
设计原则
1、针对于数据量较大,且查询比较频繁的表建立索引。 2、针对于常作为查询条件 (where)、排序(order by)、分组 (group by)操作的字段建立索引。 3、尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。 4、如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引。 5、尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。
6、要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。 7、如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个7索引最有效地用于查询。
mysql索引使用
参考网站:https://www.begtut.com/mysql/mysql-index.html
添加索引
CREATE INDEX idx_name on tablename(filed);
CREATE INDEX idx_name_age on user(name,age);
alert table user add index index_email (email);
# 唯一索引(字段值可以为null)
CREATE UNIQUE INDEX index_phone on user (phone);
alert table user add unique (phone);
# 逐渐索引(字段值不能为null)
CREATE PRIMARY KEY INDEX index_phone ON user (phone);
alert table user add primary key (phone);
演示
SELECT count(1) from tableName;
select * from tableName where user.phone='123456789'
查看索引
show index from user;
删除索引
drop index idx_name on jokes;
联合索引
索引选择
- 经常使用到的列在最左边
- 选择性高的列优先
- 宽度小的列
排序优化
- 要求where子句使用的所有字段,都必须建立索引;
- 不要在
索引列上面做任何操作(计算、函数),否则会导致索引失效而转向全表扫描 - 索引的列顺序和
order by字句的顺序完全一致 - 索引中多有列的方向(升序,降序)和
order by子句完全一致 order by中的字段全部在关联表中的第一张表中
select * from table where colume > 10 order by u
注意事项
- like %keyword 索引失效,使用全表扫描。但可以通过翻转函数+like前模糊查询+建立翻转函数索引=走翻转函数索引,不走全表扫描。
- like keyword% 索引有效。
- like %keyword% 索引失效,也无法使用反向索引。
not in和<>不能使用索引
可参考:https://www.cnblogs.com/yizhiamumu/p/9055531.html
https://blog.csdn.net/weixin_28973649/article/details/116112874
CREATE INDEX idx_id_title on jokes(id,title);
CREATE INDEX idx_id on joke_cates(id);
SELECT count(1) FROM jokes;
SELECT * FROM jokes WHERE id < 1000;
select * from jokes where title like '搞笑%'
EXPLAIN select title from jokes where title like '%搞笑%'
添加演示数据
https://downloads.mysql.com/docs/sakila-db.zip
优化案例
order by 查询太慢
索引的列顺序和
order by子句的顺序完全一致索引中所有的列的方向(升序,降序)和
order by子句完全一致order by中的字段全部在关联表的第一张表order by的字段是主表(个人理解)
1、配置,当内存比较大的时候可以适当放大这个值
sort_buffer_site
2、建立索引
加入我们需要需要进行id倒叙查询
select * from jokes where cate_id=1 order by id limit 15
索引创建: 创建一个以 where 条件进行查询的联合索引
create index idx_cate_id_id on jokes(cate_id,id);
3、回表生成结果集
当行小于 max_length_for_sort_data 会生成全字段中间结果集
用户查询
# 用户统计
select count(1) from million_users; # 2 s 823 ms
# 查看寻一个用户
select * from million_users where id=5600; # 89 ms
select * from million_users order by id desc limit 20; # 89 ms
select * from million_users where money > 1000 order by id desc limit 20; # 79 ms
# 下面这两个也是耗时的查询
select * from million_users where name="橙留香" and password="caVLvYBY8HfRjGSOaM99jHSyM8o7Gv"; # 5 s 606 ms
select * from million_users where name like "hlubo%" order by id desc limit 20; # 5 s 827 ms
# 查看所有
show index from million_users;
# 创建索引
create index idx_name_password on million_users(name,password);
# 删除索引
drop index idx_name_password on million_users;
# 有索引的情况下查询
select * from million_users where name="橙留香" and password="caVLvYBY8HfRjGSOaM99jHSyM8o7Gv"; # 74 ms
select * from million_users where name like "hlubo%" order by id desc limit 20; # 107 ms
关联统计优化
通过【文章分类】统计该分类下面的【文章】数
| joke | joke_cate |
|---|---|
| id,cate_id | id |
优化建议: 在 joke 中创建一个 cate_id 字段的索引
create index idx_cate_id on joke(cate_id);
Mysql占用空间统计
「所有库」的容量大小
SELECT
table_schema as '数据库',
sum(table_rows) as '记录数',
sum(truncate(data_length/1024/1024, 2)) as '数据容量(MB)',
sum(truncate(index_length/1024/1024, 2)) as '索引容量(MB)',
sum(truncate(DATA_FREE/1024/1024, 2)) as '碎片占用(MB)'
from information_schema.tables
group by table_schema
order by sum(data_length) desc, sum(index_length) desc;
MySQL 数据库中容量排名前 10 的表
USE information_schema;
SELECT
TABLE_SCHEMA as '数据库',
table_name as '表名',
table_rows as '记录数',
ENGINE as '存储引擎',
truncate(data_length/1024/1024, 2) as '数据容量(MB)',
truncate(index_length/1024/1024, 2) as '索引容量(MB)',
truncate(DATA_FREE/1024/1024, 2) as '碎片占用(MB)'
from tables
order by table_rows desc limit 10;
「指定库」中,容量排名前 10 的表
USE information_schema;
SELECT
TABLE_SCHEMA as '数据库',
table_name as '表名',
table_rows as '记录数',
ENGINE as '存储引擎',
truncate(data_length/1024/1024, 2) as '数据容量(MB)',
truncate(index_length/1024/1024, 2) as '索引容量(MB)',
truncate(DATA_FREE/1024/1024, 2) as '碎片占用(MB)'
from tables
where
table_schema='laravel_web' # 表名
order by table_rows desc limit 10;
「指定库」中「指定表」的容量大小
SELECT
table_schema as '数据库',
table_name as '表名',
table_rows as '记录数',
truncate(data_length/1024/1024, 2) as '数据容量(MB)',
truncate(index_length/1024/1024, 2) as '索引容量(MB)',
truncate(DATA_FREE/1024/1024, 2) as '碎片占用(MB)'
from
information_schema.tables
where
table_schema='laravel_web'and table_name='movies'
order by
data_length desc, index_length desc;
查询技巧
经纬度范围查询
SELECT qymc,lng,lat,
(st_distance(point(lat,lng),point(116.452404,39.947689))*111195) AS distance
FROM fxxf_tsgs
HAVING distance<100
ORDER BY distance
limit 100
慢查询统计
根据慢查询总数倒序统计
mysqldumpslow -s c movie-slow.log > movie_total_desc.txt
根据慢查询时长倒序统计
mysqldumpslow -s t movie-slow.log > movie_time_desc.txt
基本命令
取消root密码
ALTER USER 'root'@'localhost' IDENTIFIED BY '';
FLUSH PRIVILEGES;
开启远程访问
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '密码';
FLUSH PRIVILEGES;
关闭远程访问
DELETE FROM mysql.user WHERE User='root' AND Host='%';
FLUSH PRIVILEGES;
创建一个跟root一样权限的账户
CREATE USER 'system_user'@'%' IDENTIFIED BY 'admin666';
GRANT ALL PRIVILEGES ON *.* TO 'system_user'@'%' WITH GRANT OPTION;
FLUSH PRIVILEGES;
查询用户
SELECT user, host FROM mysql.user;
删除用户
DROP USER 'new_root'@'%';
DROP USER 'new_root'@'localhost';
用户操作
# 显示所有用户
SELECT host,user from mysql.`user`;
# 创建用户
create user demo@'%' identified by '123456';
# 查看用户信息
select user,host,plugin from mysql.user;
# 修改用户密码
alter user demo@'%' identified by 'new password';
# 修改用户连接方式
update mysql.user set Host='localhost' where user='demo';
# 删除用户
drop user demo@'%';
权限操作
# 查看当前用户权限
show grants;
# 查看制定用户权限
show grants for orangbus@'%';
# 授权
# grant: 关键字
# test.*: 作用域,test库所有表
# 'tom'@'192.168.150.%': 哪个用户
grant select,update,insert on test.* to demo@'%';
# 授予所有权限
grant all privileges on *.* to demo@'%';
# 授予用户授权其他用户权限的权限
grant select,insert,update,delete on test.* to demo@'%' with grant option;
# 删除用户权限
revoke insert on test.* from demo@'%';
# 删除授予权限
revoke grant option on test.* from demo@'%';
# 删除所有权限
# revoke仅删除权限, 不删除用户
# revoke all 后还是会有一个USAGE 权限
revoke all on test.* from demo@'%';
数据库操作
# 创建
CREATE DATABASE 数据库名;
# 删除
drop database 数据库名;
------
create database user;
drop database user;
表操作
# 创建表
CREATE TABLE table_name (
id INT UNSIGNED AUTO_INCREMENT,
name char(11) not null,
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
# 添加表字段
alert table tabme_name add phone char(11) first|after filed_name;
# 修改表字段
alert table table_name change phone phone varchrt(11);
# 删除表字段
alert table table_name drop phone;
# 删除表
drop table table_name;
导入sql
mysql -u username -p database_name < file.sql
导出sql
mysqldump -u username -p database_name > dump.sql
mysqldump -u username -p database_name table_name > table_dump.sql
mysqldump -u username -p --no-data database_name > structure_dump.sql
1.导出整个数据库 mysqldump -u 用户名 -p 数据库名 > 导出的文件名 mysqldump -u dbuser -p dbname > dbname.sql
2.导出一个表 mysqldump -u 用户名 -p 数据库名 表名> 导出的文件名 mysqldump -u dbuser -p dbname users> dbname_users.sql
3.导出一个数据库结构 mysqldump -u dbuser -p -d --add-drop-table dbname >d:/dbname_db.sql -d 没有数据 --add-drop-table 在每个create语句之前增加一个drop table
4.导入数据库 常用source 命令 进入mysql数据库控制台,如 mysql -u root -p mysql>use 数据库 然后使用source命令,后面参数为脚本文件(如这里用到的.sql) mysql>source d:/dbname.sql
mysql导入大文件
修改该目录下my.ini文件中max_allowed_packet 因为默认max_allowed_packet为1k,如果导入的文件过大。可能会报错。 我们将该值改大一点,我这里设为1G。
[mysqld]
max_allowed_packet = 1024M
查看设置是否生效
show VARIABLES like '%max_allowed_packet%';
本地终端连接数据库导入
mysql -h 192.168.3.1 -uroot -p
use mydb;
set names utf8;
source /path/to/insertTable.sql
====
# 开启事务
start transaciton;
# 引入SQL文件
source xxx.sql
# 成功后提交事务
commit;
日志
索引失效案例
select * from `articles` where `status` = 1 and `cate_id` = 38 order by `id` desc limit 17;
CREATE INDEX idx_status_cate_id on articles(id,status,cate_id); # 失败
CREATE INDEX idx_status_cate_id on articles(status,cate_id,id); # 成功
DROP INDEX idx_status_cate_id ON articles;
日期查询
select * from `archives` where `uid` = 1 and month(`birthday`) = 6 and day(`birthday`) = 28
select count(id) from `archives` WHERE DATE(`created_at`) = "2024-06-26"
select count(id) from `archives` WHERE YEAR(`created_at`) = "2024"